SEO优化必备技能——网站日志分析
分析网站日志是SEOer的必备技能,通过对网站日志进行分析,我们可以更加清楚的了解到搜索引擎对网站爬行抓取的情况,即何时何种搜索引擎抓取了哪个URL页面以及搜索引擎是否抓取成功,抓取网页的数据量是多杀等信息。
通过对这些数据的整理分析,我们可以很清楚的了解到网站的运行状态以及搜索引擎蜘蛛的爬行状态,为后期的SEO操作提供数据基础。
思维浅析
————
说到网站日志,很多新手都觉得这个太复杂了,表示自己看不懂,更得不出指导SEO操作的结论。这么说大都是由于不清楚网站日志数据的具体含义,以及不能正确的读取网站日志文件所反映出的信息。

所谓的网站日志,并没有想象中那么深奥,简单的讲就是记录访客访问网站的轨迹和痕迹所产生的文件记录,在这里搜索引擎蜘蛛对网站的抓取可以看成网站的一种特殊访客。
01
—
在分析网站日志之前我们需要对日志文件的一些基本参数信息做个简单了解。
#Software: Microsoft Internet Information Services 6.0 #Software:表示软件名称
#Version: 1.0 #Version:表示版本号
#Date: 2013-03-13 00:05:17 #Date:表示时间
#Fields:date time s-sitename s-ip cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken (这里对应的即是网站日志文件中记录条目,各项参数的具体释义如下)
date:发出请求时候的日期。
time:发出请求时候的时间。注意:默认情况下这个时间是格林威治时间,比我们的北京时间晚8个小时,下面有说明。
c-ip:客户端IP地址。
cs-username:用户名,访问服务器的已经过验证用户的名称,匿名用户用连接符-表示。
s-sitename:服务名,记录当记录事件运行于客户端上的Internet服务的名称和实例的编号。
s-computername:服务器的名称。
s-ip:服务器的IP地址。
s-port:为服务配置的服务器端口号。
cs-method:请求中使用的HTTP方法,GET/POST。
cs-uri-stem:URI资源,记录做为操作目标的统一资源标识符(URI),即访问的页面文件。
cs-uri-query:URI查询,记录客户尝试执行的查询,只有动态页面需要URI查询,如果有则记录,没有则以连接符-表示。即访问网址的附带参数。
sc-status:协议状态,记录HTTP状态代码,200表示成功,403表示没有权限,404表示找不到该页面,具体说明在下面。
sc-substatus:协议子状态,记录HTTP子状态代码。
sc-win32-status:Win32状态,记录Windows状态代码,即http状态码。
sc-bytes:服务器发送的字节数。
cs-bytes:服务器接受的字节数。
time-taken:记录操作所花费的时间,单位是毫秒。
cs-version:记录客户端使用的协议版本,HTTP或者FTP。
cs-host:记录主机头名称,没有的话以连接符-表示。注意:为网站配置的主机名可能会以不同的方式出现在日志文件中,原因是使用Punycode编码格式来记录主机名。
cs(User-Agent):用户代理,客户端浏览器、操作系统等情况。
cs(Cookie):记录发送或者接受的Cookies内容,没有的话则以连接符-表示。
cs(Referer):引用站点,即访问来源。
02
—
尽管网站日志中的参数很多,但对我们做SEO优化来说,最需要关注的是ip地址、时间、时区、访问路径、http状态码、字节数访问页面、客户端浏览信息等参数值。
对上述的参数中重点关注以下几个:
cs(User-Agent)蜘蛛抓取量:用户代理,客户端浏览信息、操作系统等情况。
cs-uri-stem:URI资源,记录做为操作目标的统一资源标识符,即被访问(被抓取)的页面文件。
c-ip:客户端IP地址。
sc-status:协议状态,记录HTTP状态代码,200表示成功,403表示没有权限,404表示找不到该页面,500表示服务器的错误。
03
—
示例: - - [02/May/2011:01:57:44 -0700] "GET/ HTTP/" 500 19967 "-" "Mozilla/ (compatible; MSIE 8.0; Windows NT 5.1; Trident/; AskTbCS-ST/5.11.3.15590; .NET CLR 2.0.50727; Alexa Toolbar)"(如果你的日志里格式不是如此,则代表日志格式设置不同)
访问ip
02/May/2011:01:57:44 -0700 访问日期 -时区(不同日志时间格式有所差异)
GET/ HTTP/ 根据HTTP/ 协议 抓取根目录下这个页面(GET表示服务器动作,/代表根目录)
500 服务器响应状态码
19967 表示抓取了19967个字节
Mozilla/ (compatible; MSIE 8.0; Windows NT 5.1; Trident/; AskTbCS-ST/5.11.3.15590; .NET CLR 2.0.50727; Alexa Toolbar
表示访问者使用火狐浏览器及Alexa Toolbar 等访问端信息
注意:很多日志里可以看到 200 0 0和200 0 64 则都代表正常抓取。
04
—
在整个网站日志中如何区分哪些是普通访客哪些是搜索引擎呢?很简单,就是通过观察日志记录中表示访问者信息的那一段进行区别。
百度官方给出的UA如下图所示:

但需要注意的是尽管记录中的UA与百度官方给出的UA相同,也可能是伪造的百度蜘蛛UA,因此可以使用IP反查确认是否为真实的百度蜘蛛访问抓取网站。
通过DNS反查IP的方式判断spider是否来自百度搜索引擎。根据平台不同验证方法不同,如linux/windows/os三种平台下的验证方法分别如下:
1)、在linux平台下,使用host ip命令反解ip来判断是否来自Baiduspider的抓取。
2)、在windows平台或者IBM OS/2平台下,使用nslookup ip命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入nslookup xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取。
3)、 在mac os平台下,您可以使用dig 命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取。
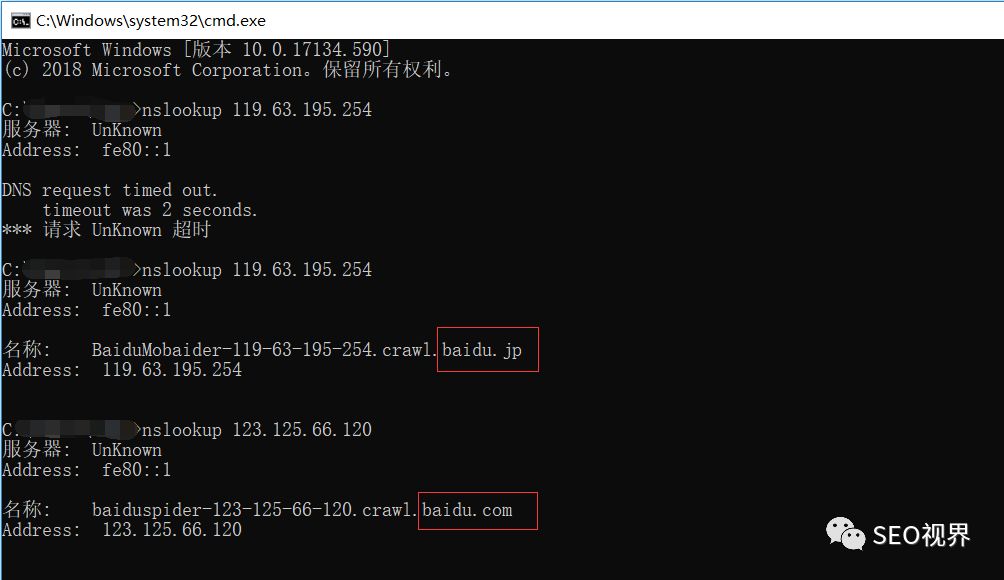
Tips:Baiduspider的hostname以 *. 或 *. 的格式命名,非 *. 或 *. 即为冒充。
写在最后
————
分析网站日志是每一位SEOer的必备技能,通过网站日志可以更加清楚的了解到搜索引擎爬行抓取网站内容的情况,同时当网站出现被黑或者挂马等情况,通过分析网站日志,也能快速的定位到可疑文件,帮助站长快速解决网站的安全隐患。
同样是做SEO,对于SEO思维和实操,不同的SEOer都有自己的见解与心得,欢迎每一位喜欢SEO的朋友留言交流!!!
转载请注明: 爱推站 » SEO优化必备技能——网站日志分析


评论列表(0)
发表评论